AI2’s Open-Source Tülu 3 Allows Anyone to Participate in the AI Post-Training Game
Ask anyone in the open source AI community, and they will tell you the gap between them and the big private companies is more than just computing power.
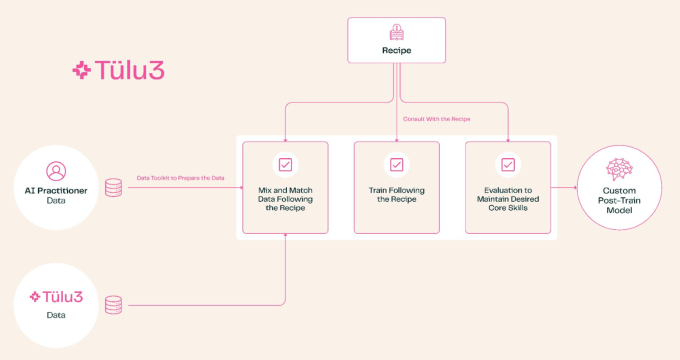
Ask anyone in the open source AI community, and they will tell you the gap between them and the big private companies is more than just computing power. Ai2 is working to fix that, first with fully open source databases and models and now with an open and easily adapted post-training regimen to turn "raw" large language models (LLMs) into usable ones.
Contrary to what many people think, "foundation" language models do not emerge out of the training process immediately ready to be put to work. Of course, pretraining is necessary-but far from sufficient. Some even believe that pretraining may soon no longer be the most important part at all.
That's because the post-training process increasingly is where real value can be created. It's there that the model is molded from a giant, know-it-all network that will as readily produce Holocaust-denial talking points as it will cookie recipes. You generally don't want that!
Firms are tight-lipped regarding their post-training regimens since, whereas anyone can scrape the web and build a model using cutting-edge techniques, turning that model into something useful to, for example, a therapist or research analyst, is an altogether different problem.
Ai2, formerly the Allen Institute for AI, has said that even in supposedly "open" AI projects like Meta's Llama, there is too little openness. The model is free for anybody to use and tinker with, but sources and procedure about how the raw model was made and how it is trained to become general-use remain closely secreted. Not bad-but also not really open-when describing truly open projects
But Ai2 is committed to openness at whatever level it can be, from exposing its data collection, curation, cleaning, and other pipelines to the exact training methods it used to produce LLMs like OLMo.
But the honest truth is that only a handful of developers have the bandwidth to run their own LLMs in the first place, and even fewer can do post-training like Meta, OpenAI, or Anthropic does — partly because they don't know how, but also because it's technically complex and time-consuming.
Fortunately, Ai2 wants to democratize this aspect of the AI ecosystem as well. That is where Tülu 3 comes in. An enormous leap forward over an earlier, much more primitive post-training process (here again dubbed, you guessed it, Tülu 2). In the nonprofit's tests, this achieved scores equal to the most advanced "open" models out there. It is based on months of experimentation, reading, and interpreting what the big guys are hinting at, and lots of iterative training runs.
Basically, Tülu 3 covers everything from choosing which topics you want your model to care about-downplaying multilingual capabilities but dialing up math and coding-and takes it through a long regimen of data curation, reinforcement learning, fine-tuning and preference tuning, tweaks of a bunch of other meta-parameters and training processes that I couldn't adequately describe to you. It results in hopefully a much more effective model targeted towards the skills that you want it to be effective at.
The real point, though, is taking one more toy out of the private companies' toybox. Previously, if you wanted to build a custom-trained LLM, it was very hard to avoid using a major company's resources one way or the other, or hiring a middleman who would do the work for you. That's not only expensive, but it also introduces risks that some companies are loath to take.
For example, medical research and service companies: Sure, you might call OpenAI's API, or you might plead with Scale or whoever to modify an in-house model, but both of those require external companies working with sensitive user data. If that can't be avoided, well, too bad — but otherwise? Such as if, say, a research group opened up the floodgates for a soup-to-nuts pre- and post-training regimen that you could run inhouse? That may well be a better alternative.
Ai2 is using this itself, which is the best endorsement one can give. Even though the test results it's publishing today use Llama as a foundation model, they're planning to put out an OLMo-based, Tülu 3-trained model soon that should offer even more improvements over the baseline and also be fully open source, tip to tail.